
了解大数据分析的四大支柱
了解大数据分析的四大支柱
“大数据”这一术语涵盖了使用技术在合理的时间范围内捕获、处理、分析和可视化潜在的大型数据集,而标准 IT 技术无法实现这些数据集。” 由此延伸,用于此目的的平台、工具和软件统称为“大数据技术” - NESSI (2012)
介绍
如果我们能理解近年来人们热议的“大数据”这个词,那岂不是很棒?一个围绕这个术语的行业正在发展,提供以数据为中心的服务,声称可以通过各种方式增强您的业务。
请不要误会——我确实相信其中的一些说法。
重要的是要明白,尽管你可能才刚刚开始听到人们谈论大数据,但这个问题领域已经存在很多年了。自 25 年前互联网兴起以来,数据可用性已大幅增长。此外,一旦商业公司了解到用户流量、用户活动和其他数据可以转化为有用的商业信息,他们就会对数据产生浓厚的兴趣。大学和研究人员也了解访问大量数据的力量。这些领域的人们现在可以随时获得更多信息,并且可以高效地处理曾经难以想象的大量数据。
在本文中,我希望逐步了解当今大数据分析的主要完成方式。
概述
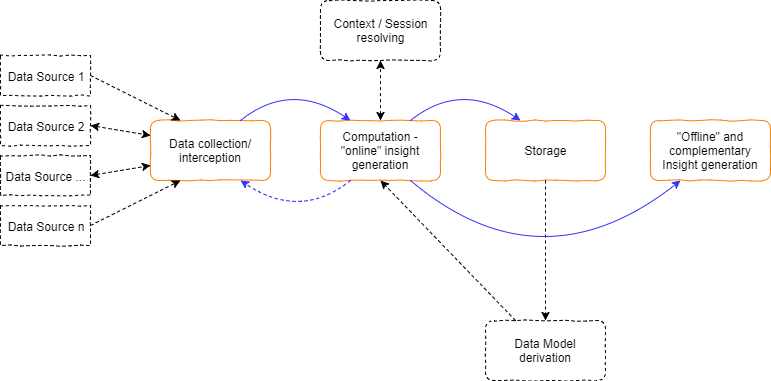
在本文中,我们将描述典型大数据分析平台中的“活动部件”。我说“典型”是因为可能存在其他方法,这些方法也会对您的企业或研究有益。但是,根据我的经验,以下方法最常见且最有效。对于我们研究的每个支柱(或角色),我将解释它如何融入大局,并提及该角色的具体职责。
对于每个这样的角色,我都会提到相关的流行技术,这些技术可以很好地作为适合大数据分析总体任务的实现。
四大支柱的共同关切
数据分析平台和“大数据”分析平台之间有什么区别?为什么“传统”方式不够用?我们不能简单地编写一个应用程序,通过任何标准应用程序接口 (API) 接收数据,解析和提取数据,最后显示一些有趣的见解吗?
我们可以,但要有限度。对于昂贵的操作,我们的资源很快就会达到极限。任何一台现代机器,无论它有多快,拥有当今可以买到的最快的存储和网络设备,在给定时间内可以管理的数据量仍然有上限。
使用单台机器时,另一个担忧是系统本身是单点故障。硬件会在某个时刻出现故障。这可能意味着数据丢失和企业效率低下。
考虑到这些问题,我们明白我们期望的系统应该是:
•可扩展——能够克服任何单台机器可能存在的数据管理限制。
•容错——即使发生意外情况(如硬盘故障或电涌),仍能保持运行。
满足这两个要求意味着我们的系统需要:
•分布式——易于扩展并兼容其他资源,从而提高其数据管理能力的上限,例如收集、处理、存储、复制、收集见解等。
由于我们的系统是作为技术链构建的,因此我们需要确保链中的每个环节都符合我们的要求。让我们开始吧。
收集——数据主干
正如预期的那样,我们的旅程从数据开始😊。更具体地说,从数据收集和拦截开始。
拉取数据
在某些情况下,我们的系统会主动向相关数据源请求数据。在这种情况下,我们会说我们的系统从这些数据源提取数据。这种情况的一个例子可能是定期查询数据库,并消耗其结果。
推送数据
在其他情况下,我们的系统将注册从数据源接收数据,并在新数据可用时接收数据。在这种情况下,我们会说系统通过推送机制从这些数据源接收数据。这种情况的一个例子可能是使用 Logstash 等技术,我们可以将其配置为将数据从(几乎任何)数据源传递到我们的系统入口点。
数据主干的作用
我们决定使用的技术(或多种技术)标志着我们系统的第一个支柱——数据主干。数据主干是我们系统的入口点。它的唯一职责是将数据传递到我们数据分析平台中的其他链接。
但我们不要犯过于简单化的错误。虽然数据主干的作用单一,但这并不是一件容易的事!
我提醒你,数据主干需要在不断变化的传入数据速率下具有可扩展性和容错性——这些数据可能是短暂的数据突发或大量数据的恒定流。
我们数据主干网的功能将决定我们是否会丢失重要数据!
在某些情况下,数据只会产生一次,如果我们没有及时“捕捉”它,我们将永远失去它。因此,在这种情况下,数据收集方案必须严密无懈可击。
为了结束我们关于数据主干的讨论,我想总结一下我们在大数据分析系统中对这个特定角色的要求。
• 我们的数据主干作为数据收集和接收机制,有望向系统的其余部分提供数据——无论它如何获取这些数据,是通过拉取机制主动获取还是通过推送机制被动获取。
• 由于数据源的特性可能各不相同,我们的数据主干应该足够简单,以便于集成。使用标准 API 协议可能会使您的企业受益。
• 为了确保数据主干的可靠性,我们需要它具有可扩展性和容错能力。
在 Pluralsight 课程“构建企业级分布式在线分析平台”中可以看到使用出色的Apache Kafka创建和利用数据主干的示例。
“在线”分析——计算层
一旦我们建立了坚如磐石的数据主干,数据就可以可靠地传输到我们系统的其余部分。
一旦有新数据到达,我们可能就想观察它并确定它是否对我们特别感兴趣。
当有新的数据集到来时,可能出现以下情况:
• 新的数据集在逻辑上是完整的,可以直接从中生成见解。例如,我们正在监视的特定事件,如成人监控系统中的“按下紧急按钮”事件。
• 新数据集在逻辑上是完整的,当与上下文相关时,可以生成有关它的见解。例如 - 在线购物网站上的“添加到购物车”事件,而五分钟内没有发生“付款”事件。
• 新数据集是逻辑数据集的一部分,尚未组成。例如,我们已收到卫星图像的一部分,但只想在所有图像部分可用后对其进行分析。
• 新的数据集是逻辑数据集的一部分,当与上下文相关时,可以对其产生见解。
这里的一个常见例子是视频片段,它由多个帧组成,每个帧有多个数据包。
The role of the computation layer is to provide you with the tools to do just that – contextualize and complement any given dataset so that we can answer analytical questions.
Let’s consider the following diagram:
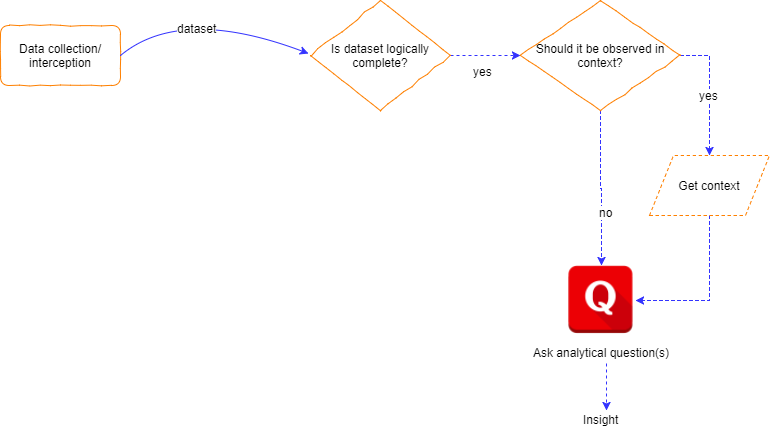
Assuming a fresh dataset arrived at our computation layer, we will possibly need to verify that it is logically complete. If it isn’t, we will probably persist it and wait until we have a logically complete dataset (hopefully, in the future).
But then again, if it is logically complete, we might want to ask analytical questions about it. In other words, we would like to perform a computation on it.
As previously mentioned, we might want to observe any logical dataset in context.
Here lies an interesting aspect of the computation layer in big data systems.
As our computation layer is a distributed system, to meet the requirements of scalability and fault-tolerance – we need to be able to synchronize it’s moving parts with a shared state. This shared state mechanism will be a blazing fast persistence / caching technology. Each dataset which arrives at our computation layers gate, will have to be persisted at the context-providing mechanism prior to any computation.
Real Life Example
For example, say we have a rather “naive” analytical question: we would like to know how many orders of a specific product were placed every minute.
To fnd an answer, we’ve implemented a means of solving this analytical question in our computation layer.
As we are expecting a massive flow of events, we’ve scaled our computation layer and we have multiple processes listening to these order events.
Now – process #1 receives an order for product A. it counts it and checks if the counter passed the threshold for insight generation. If it did – an insight is generated.
Simple enough, right? Wrong.
This implementation does not take into consideration the possible (and very likely) scenario where order events arrive at multiple processes simultaneously.
That means that our order event counter should be synchronized.
And that is why we need an external (to a computation layer process) synchronized context provider to whom all context-aware analytical questions refer to.
Getting Assistance From a Data Model
One last thing worth mentioning – if you’ve noticed, the first diagram in this article includes an optional entity named “data model derivation” which is linked to the computation layer as well as to the shortly reviewed storage layer.
When referring to a data model, in the realm of big data, we usually refer to data of interest organized in a manner that is suited for analytic derivation.
例如,我们可能有一个数据模型,其中聚合了蜂窝数据使用情况,按城市进行划分,并在逻辑上以决策树的形式保存。
给定一个预先计算的数据模型,我们的大数据分析系统可以在寻找新的见解时关联到已经计算的结果(甚至是见解)。
很常见的数据模型是:
持久保存在我们的存储层中。
有时,我们的数据模型是单独保存的,使用的技术与我们用于“在线”持久性需求的技术不同。例如,我们可能使用Apache Cassandra作为我们的首选持久性,因为它具有极快的写入速度和性能可扩展性。但是,我们可能会使用不同的技术来持久化我们将“离线”分析的大型数据文件,因为它具有快速的读取性能。
以“离线”方式定期计算。
这通常是出于必要:在大型数据集上执行高耗时(时间、CPU、I/O)计算是资源密集型的。任何我们不想牺牲宝贵的计算资源来“在线”执行的事情都应该留到以后的“离线”计算中去做。
预加载到计算层,以两种方式与其相关:
从中读取数据,以得出见解。
将新数据写入其加载的表示中,因此它保持“最新”,直到我们获得新计算的数据模型。
上下文解析作为约束
现在,让我们暂停一下,了解一下数据分析的一个最重要的方面,这在处理“大数据”时会变得更加重要。
我们在特定时间内能够处理的数据量是有限的。
确实,有了可扩展的系统,我们可以将极限推得更高,但在某个离散的时间点,限制就会存在。
这些限制在“在线分析”标题下尤其重要,因为“在线”一词可以翻译为“足够接近数据创建时间”。反过来,“足够接近”可以翻译为特定时间段 - 特定于您的业务需求。
上下文解析首先依赖于进程间通信。持久化和检索数据集的上下文元数据需要我们“伸出援手”并从外部机制请求服务。
更糟糕的是,这种外部机制是一种同步机制,这意味着(至少在逻辑上)资源锁定是立即发生的!
还有上下文元数据持久性的问题。并非所有数据都可以(也绝对不应该)存储在内存中。我不需要提醒你,我们生活在一个分布式生态系统中。我们有多个进程,在多台物理机器上运行。我们的本地内存是物理机器本地的。
To top that, we are dealing with “big data.” We might have so much data at our gate that we simply cannot hold it in memory entirely.
So we understand that our synchronized context provider has to both synchronize and persist data.
We also understand that synchronization and persistence of data takes time.
If you look back at the title of this subject, you will notice that it refers to “online” analytics.
Generally, we are required to analyze any incoming dataset within a limited amount of time. If our computation time plus the time cost of our interactions with the context provider exceeds our time limit, our system is inviable for “online” work.
A computation layer, built using Apache Storm, and integrated with a full-blown analytics system, can be seen here.
Persisting - The Storage Layer
Though we’ve already mentioned the storage layer in our discussion of the previous “Pillars”, or layers as I usually refer to them. Let’s examine our requirements from a big data analytics compliant storage layer:
Our storage layer must be able to persist incoming data very fast or else we'll run into a system bottleneck that will crush our system's "online" viability.
Making things interesting, it must be able to manage changing rates of incoming data. We would like to be able to change the scale of our storage layer on demand.
Losing data is something none of us desires in an enterprise-grade data analytics system; our storage layer must be reliable.
In terms of reliability, we would also like to make sure our system can <
免责声明:本内容来源于第三方作者授权、网友推荐或互联网整理,旨在为广大用户提供学习与参考之用。所有文本和图片版权归原创网站或作者本人所有,其观点并不代表本站立场。如有任何版权侵犯或转载不当之情况,请与我们取得联系,我们将尽快进行相关处理与修改。感谢您的理解与支持!





































请先 登录后发表评论 ~