
BigML 入门
介绍
BigML 是一款托管在BigML.com上的机器学习软件。您可以使用此平台执行基本的数据预处理和可视化,甚至无需编码经验即可构建机器学习模型。监督模型(线性回归、逻辑回归、深度网络等)和非监督模型(聚类、异常、关联等)都可以在此平台上进行训练和测试。
对于初学者,BigML 提供了灵活性,可以免费在最大大小为 10KB 的数据集上构建模型。本指南将演示如何创建时间序列数据预测的端到端项目,让您清楚地了解如何启动自己的 BigML 项目。该项目涉及的主要步骤包括:
- 导入时间序列数据集
- 数据预处理
- 建立机器学习模型
- 将模型应用于测试数据集
导入时间序列数据集
从 R 导出 AirPassengers 数据集或从Kaggle下载为 CSV 文件。此数据集有两列,Month和 **#Passengers **。所有特征均无缺失值或无效值。Month 列的数据格式为YYYY -MM。以下是数据的预览:
| 月 | #乘客 |
|---|---|
| 1949-01 | 112 |
| 1949-02 | 118 |
| 1949-03 | 132 |
| 1949-04 | 129 |
| 1949-05 | 121 |
要将数据集上传到 BigML 仪表板,首先创建一个新项目并将其命名为时间序列预测。
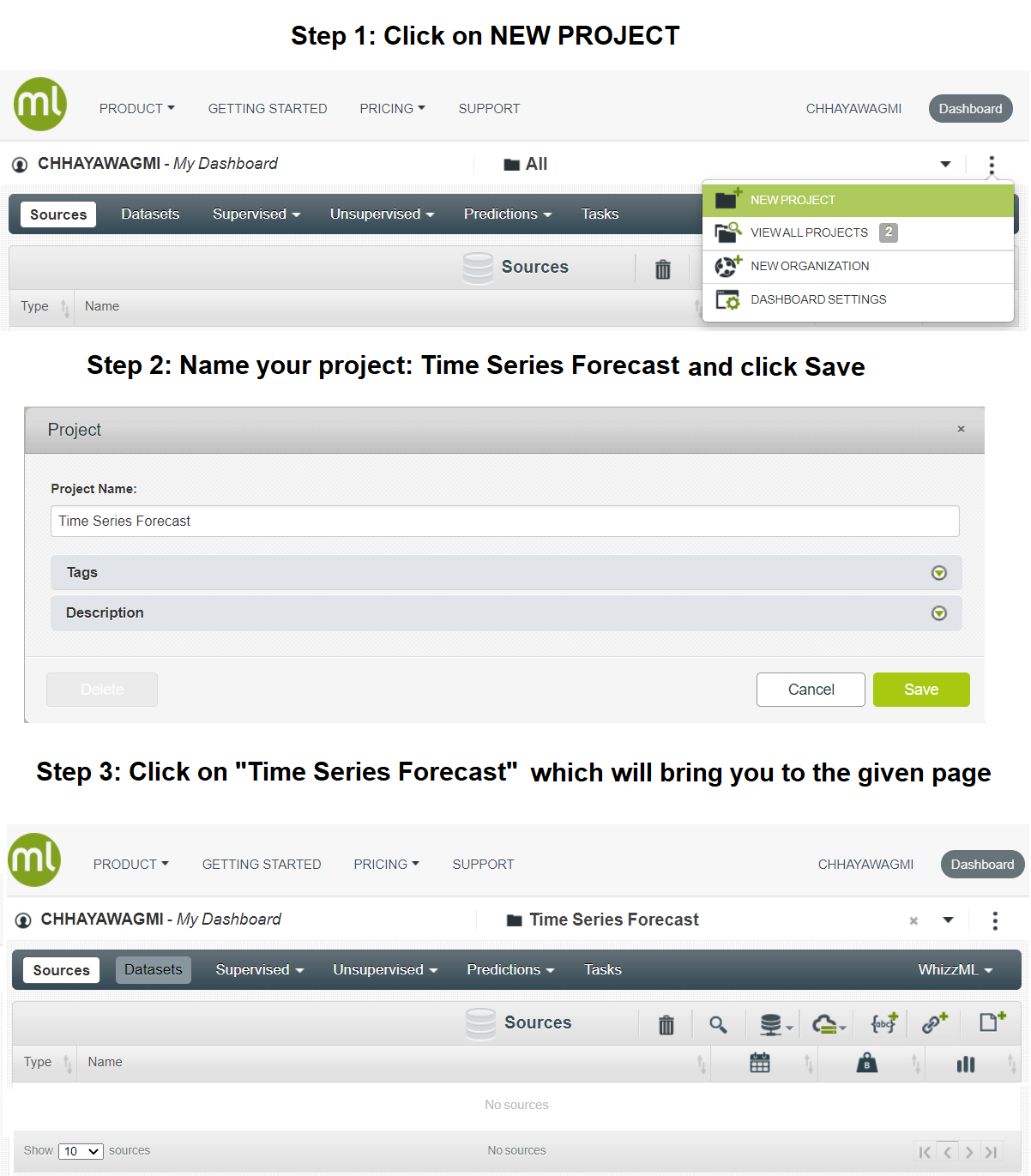
如上图所示,您的项目中目前没有可用的来源。要将数据集放入来源中,请单击最右侧的图标并上传Airpassengers.csv文件。这将打开一个绿色栏弹出窗口。
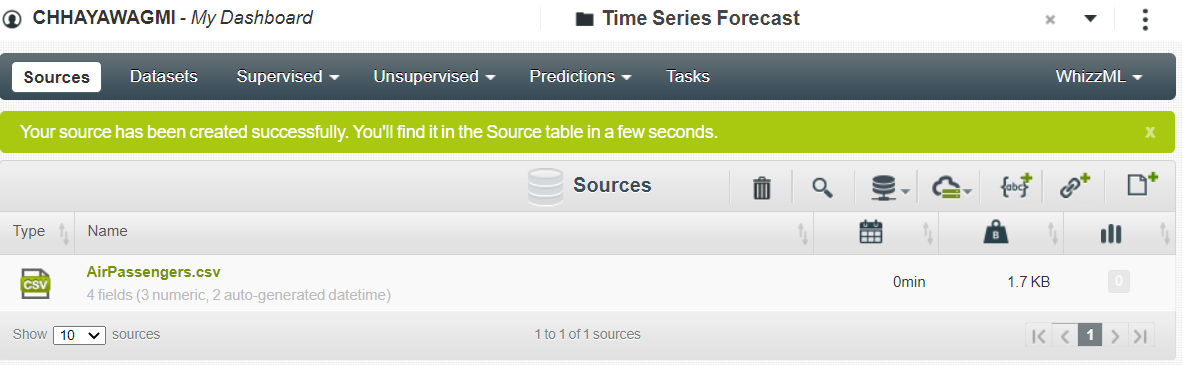
该数据集大小仅为 1.7KB,因此您可以继续进行数据预处理。
数据预处理
单击数据集,您将看到以下屏幕,它包含四个特征:
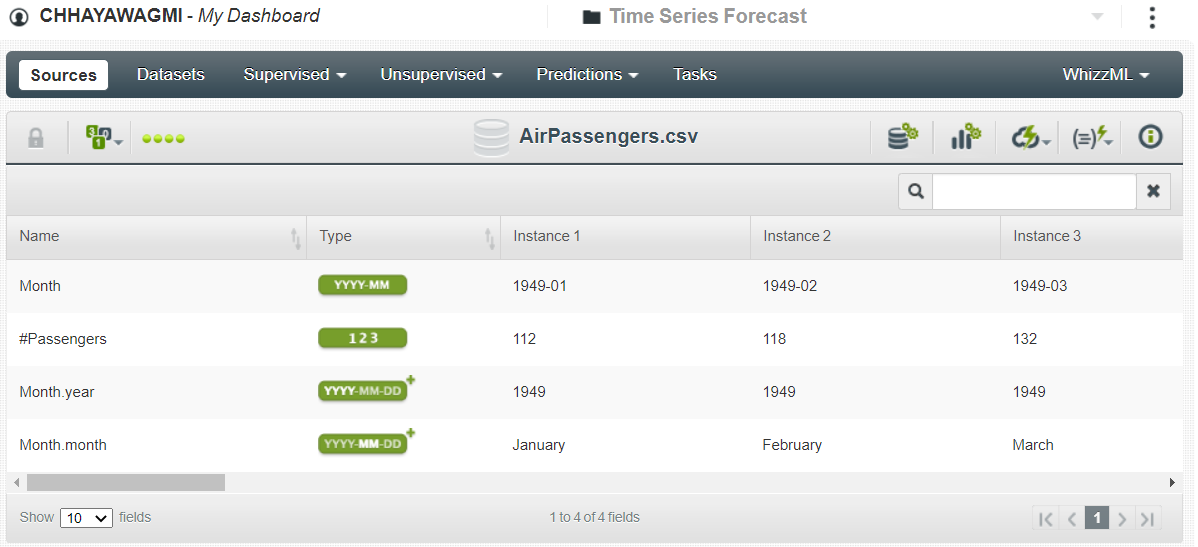
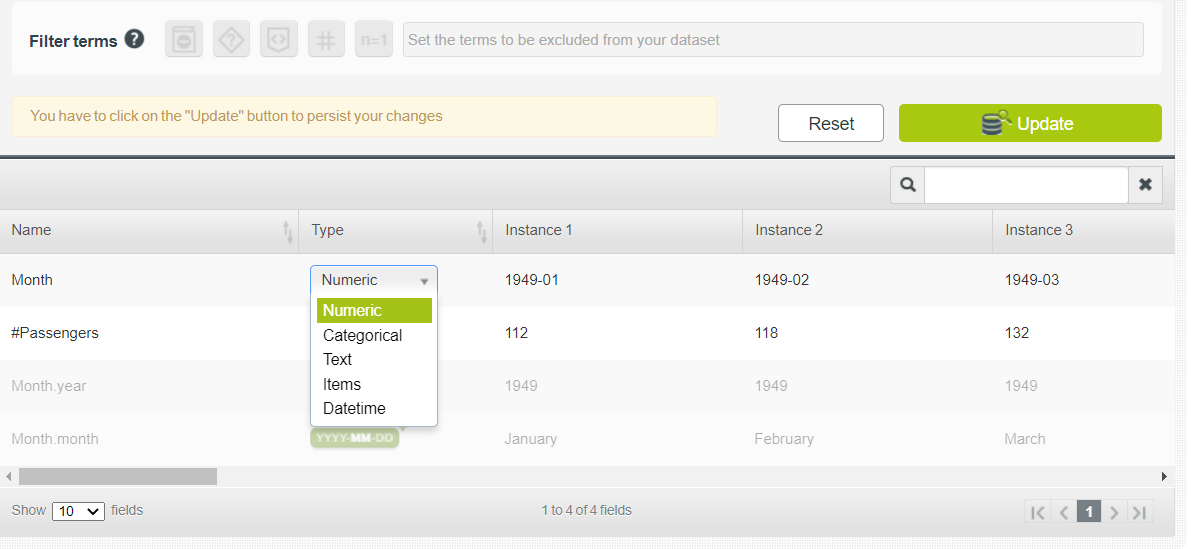
一开始只有两个特征,但现在 BigML 将第一个特征Month分解为Month.year和Month.month。要仅保留前两个特征,请单击配置源按钮并将Month的数据类型从Datetime更改为Numeric。设置数据类型后,单击更新。
您是否注意到您仍在“来源”中工作?要创建给定两个特征的数据集,请单击“1-CLICK DATASET”按钮。
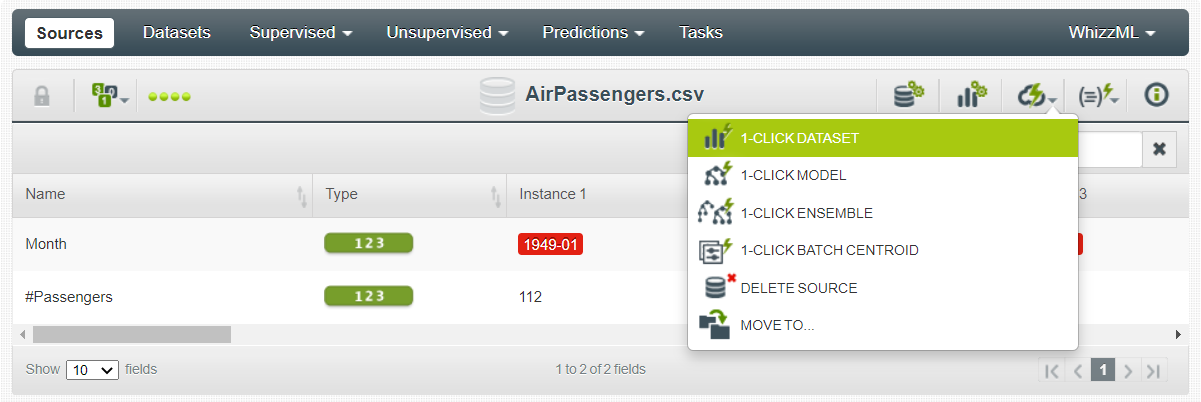
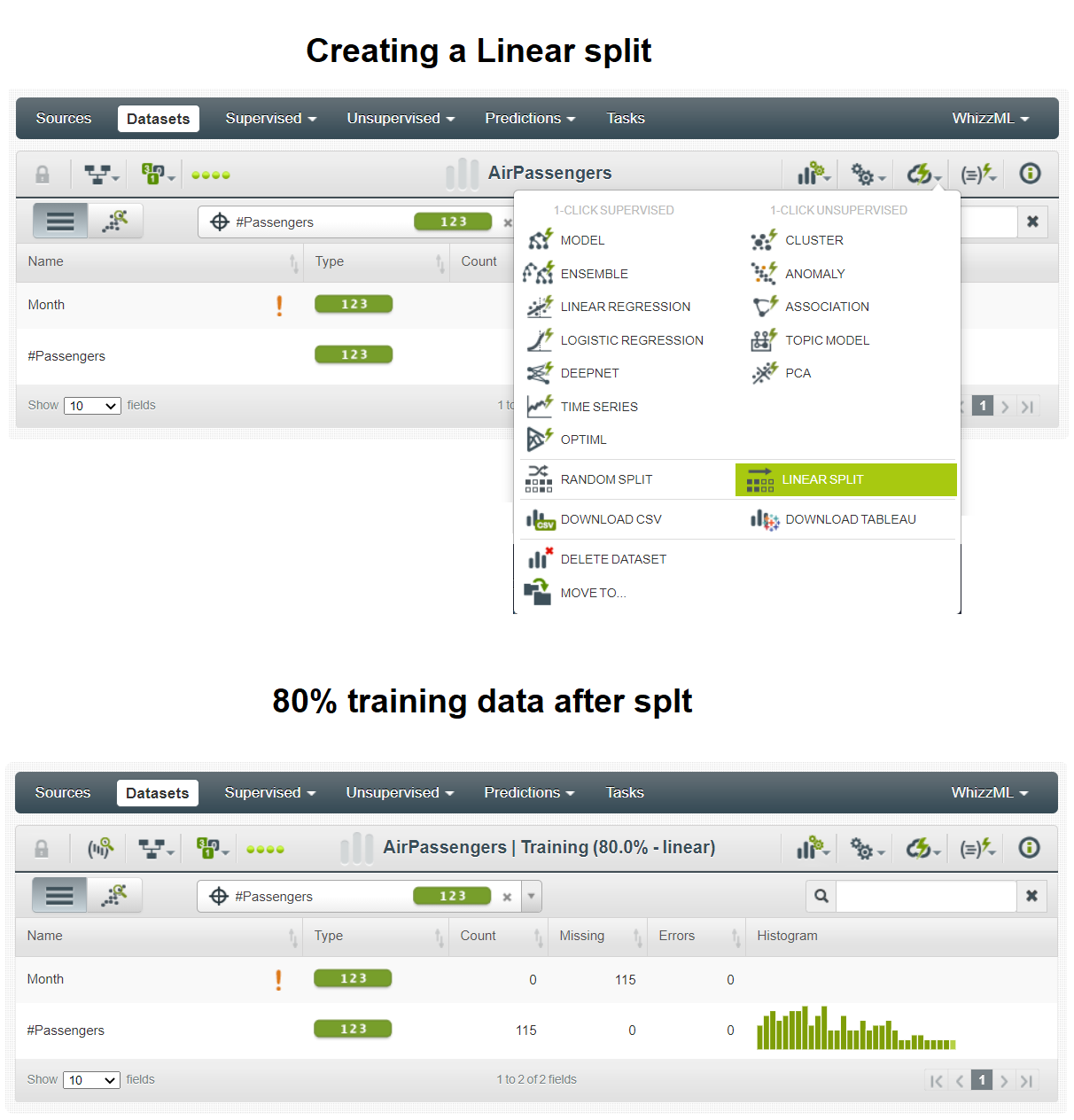
这会将您从“来源”迁移到“数据集”选项卡。接下来,您需要将整个数据集拆分为两个单独的数据集,一个用于训练模型,另一个用于测试模型。由于您目前正在处理时间序列数据集,因此您应该只执行线性拆分(严格禁止随机拆分)。为此,请单击“线性拆分”按钮,这将启动拆分过程。拆分后,训练数据将获得总观测值的 80%(144 个中的 115 个)。
建立机器学习模型
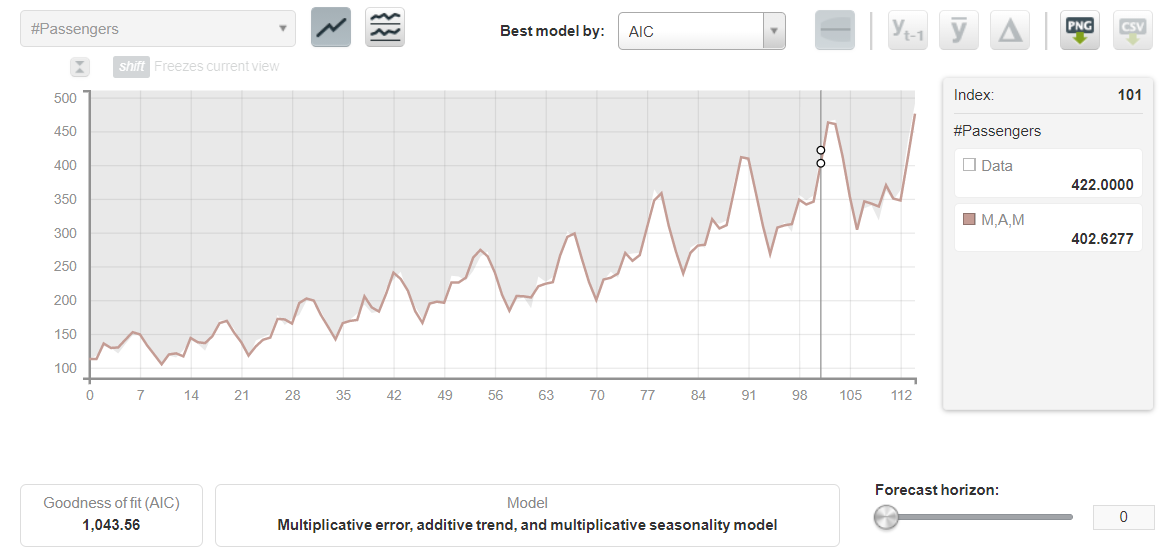
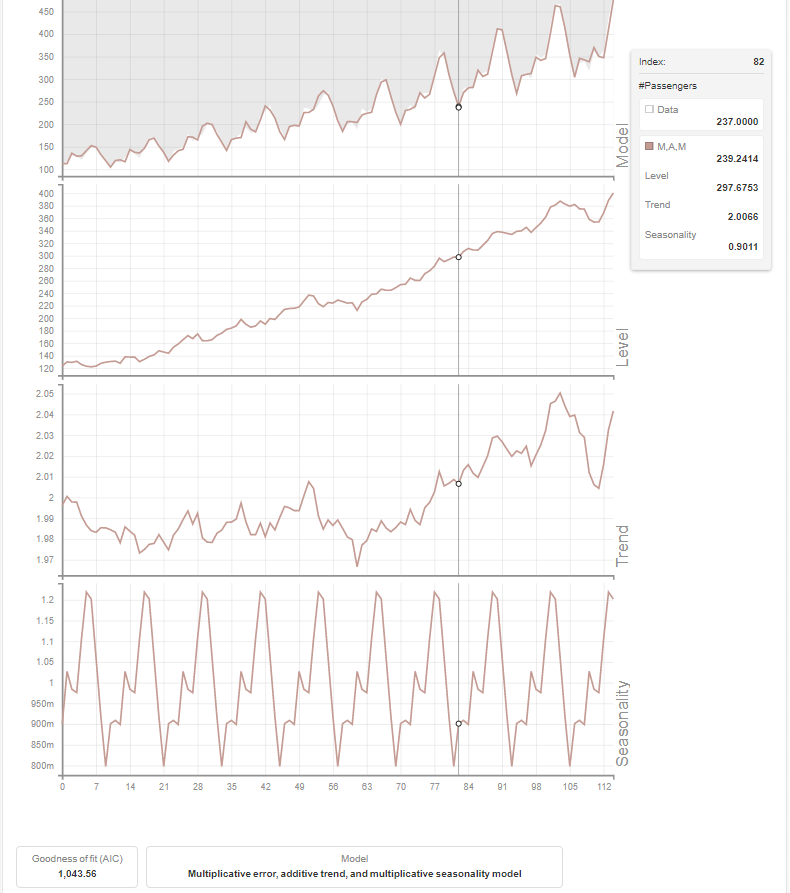
如果您曾经在 R 中预测过时间序列数据,那么您必须熟悉auto.arima()函数,该函数可从各种模型中呈现最佳拟合模型。BigML 还会在数据集上创建多个预测模型,并首先选择具有最佳指标的模型。您还可以根据 AIC、AICc、BIC 和 R 平方等指标将最佳拟合模型与其他模型进行比较。除了呈现最佳拟合模型外,您还可以可视化分解后的模型及其级别、趋势和季节性。
要开始在数据集上构建预测模型,请单击“时间序列”按钮。
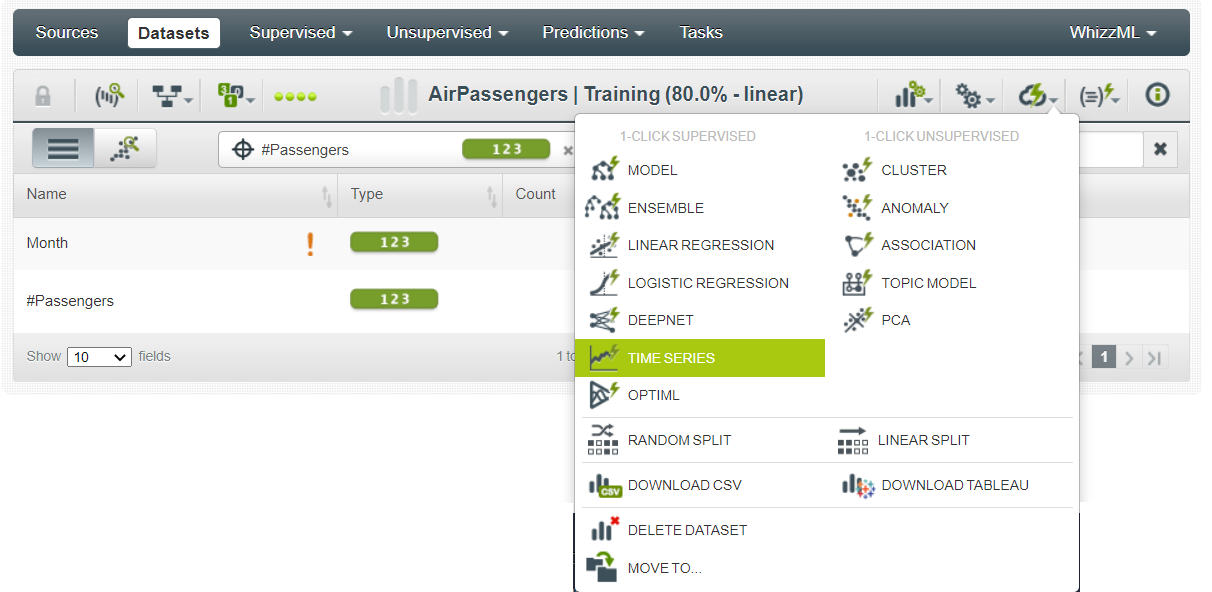
这将向您显示一个仪表板,其中包含有关最佳模型、其他模型和分解模型的所有信息。

将模型应用于测试数据集
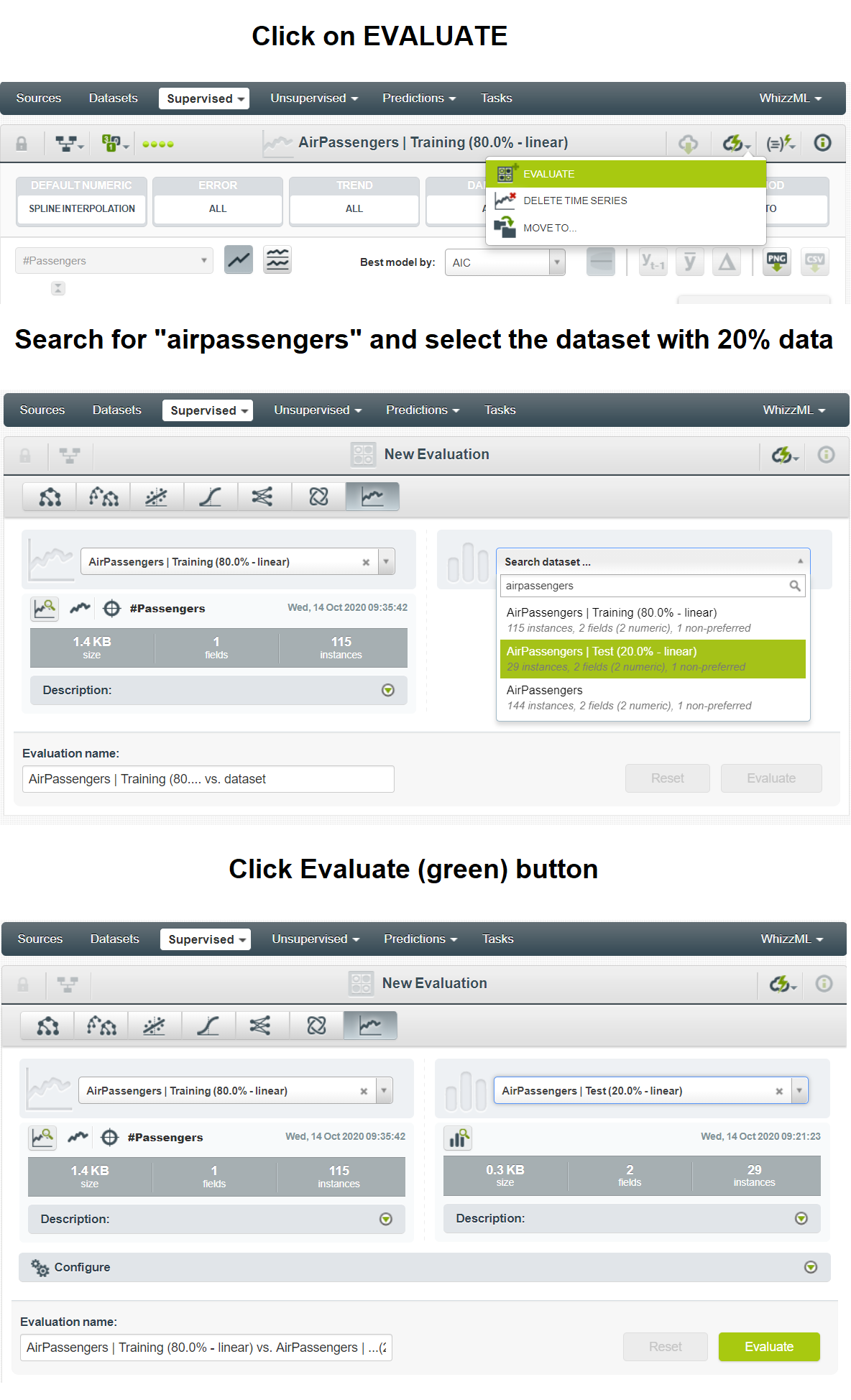
到目前为止,您已经在训练数据集上构建了模型。现在,您需要将此模型应用于测试数据集中剩余的 20% 数据。为此,请单击“评估”按钮,选择测试数据集,然后单击绿色的“评估”按钮。
评估后,您将收到一个包含原始训练、测试和预测数据的仪表板。下面给出了前三个最佳模型的预测。测试数据在突出显示的区域中有所区分。
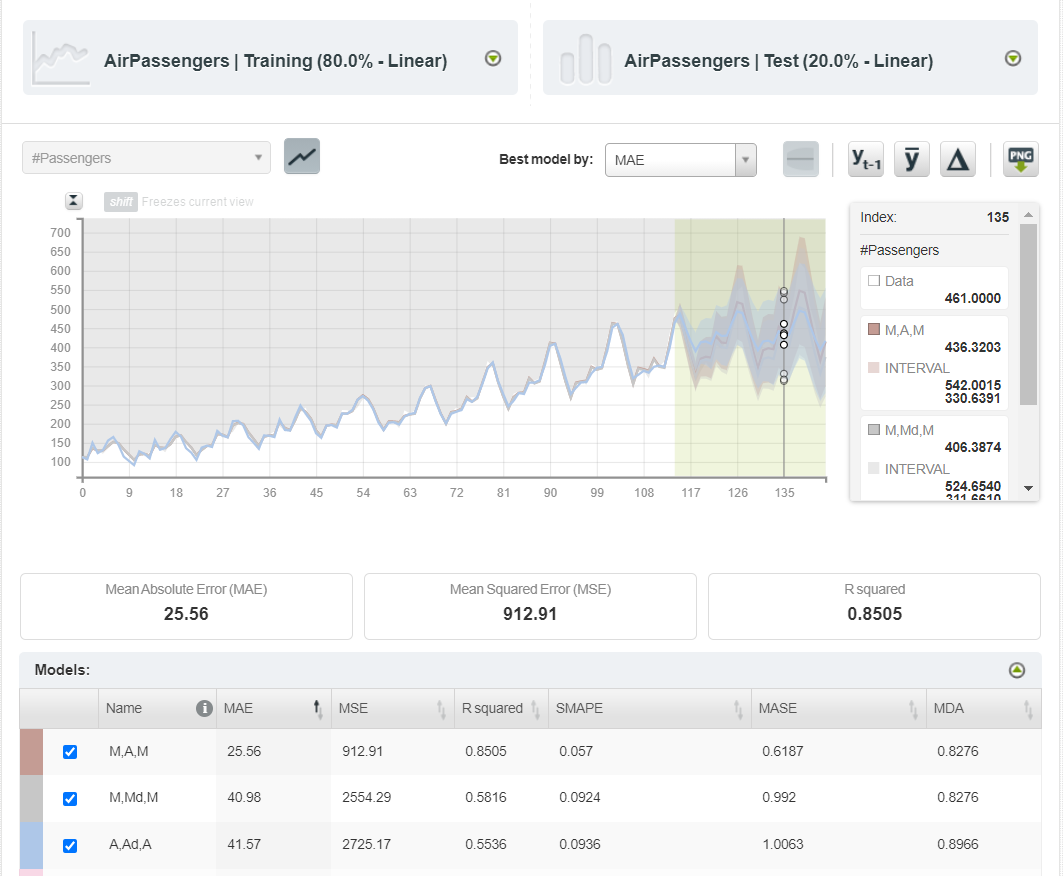
您可以根据任何可用模型预测原始数据,并且如果需要,可以将图表导出为带有或不带有图例的 PNG 图像。
结论
BigML 拥有高效、先进的基础设施,支持数据处理、可视化和构建监督/无监督机器学习模型。目前,它有九个内置数据集,甚至可以让您免费上传自己的数据集(最大 10KB)用于实践。本指南介绍了一个端到端项目(导入/配置数据集和构建/评估模型),帮助您开始使用 BigML。Pluralsight 课程利用在线资源进行 Python 分析还介绍了用于构建和共享分析的 BigML。如需更详细的研究,您可以随时参考BigML 文档。
免责声明:本内容来源于第三方作者授权、网友推荐或互联网整理,旨在为广大用户提供学习与参考之用。所有文本和图片版权归原创网站或作者本人所有,其观点并不代表本站立场。如有任何版权侵犯或转载不当之情况,请与我们取得联系,我们将尽快进行相关处理与修改。感谢您的理解与支持!





































请先 登录后发表评论 ~