
使用 Azure ML Studio 清理数据
介绍
对于数据科学家或机器学习工程师来说,数据准备是一项耗时但极其重要的活动。未能执行此操作会导致错误的见解和糟糕的建模结果。在本指南中,您将学习如何执行常见的数据清理任务,例如处理缺失值、从数据中删除重复项以及在 Azure ML Studio 中转换数据类型。
数据
在本指南中,您将使用 600 个观测值和 9 个变量的虚构数据,如下所述。
UID——申请人的唯一标识符。
受抚养人- 申请人的受抚养人人数。
Is_graduate - 申请人是否为毕业生(“是”)或不是(“否”)。
收入——申请人的年收入(以美元计)。
Loan_amount-提交申请的贷款金额(以美元计)。
信用评分- 申请人的信用评分是良好(“满意”)还是不佳(“不满意”)。
年龄— 申请人的年龄。
目的——申请贷款的目的。
审批状态- 贷款申请是否已获批准(“1”)或未获批准(“0”)。这是因变量。
加载数据
登录 Azure 机器学习工作室帐户后,您将看到以下窗口。
首先,单击左侧边栏列出的“实验”选项,然后单击“新建”按钮。接下来,单击空白实验,将显示以下屏幕。
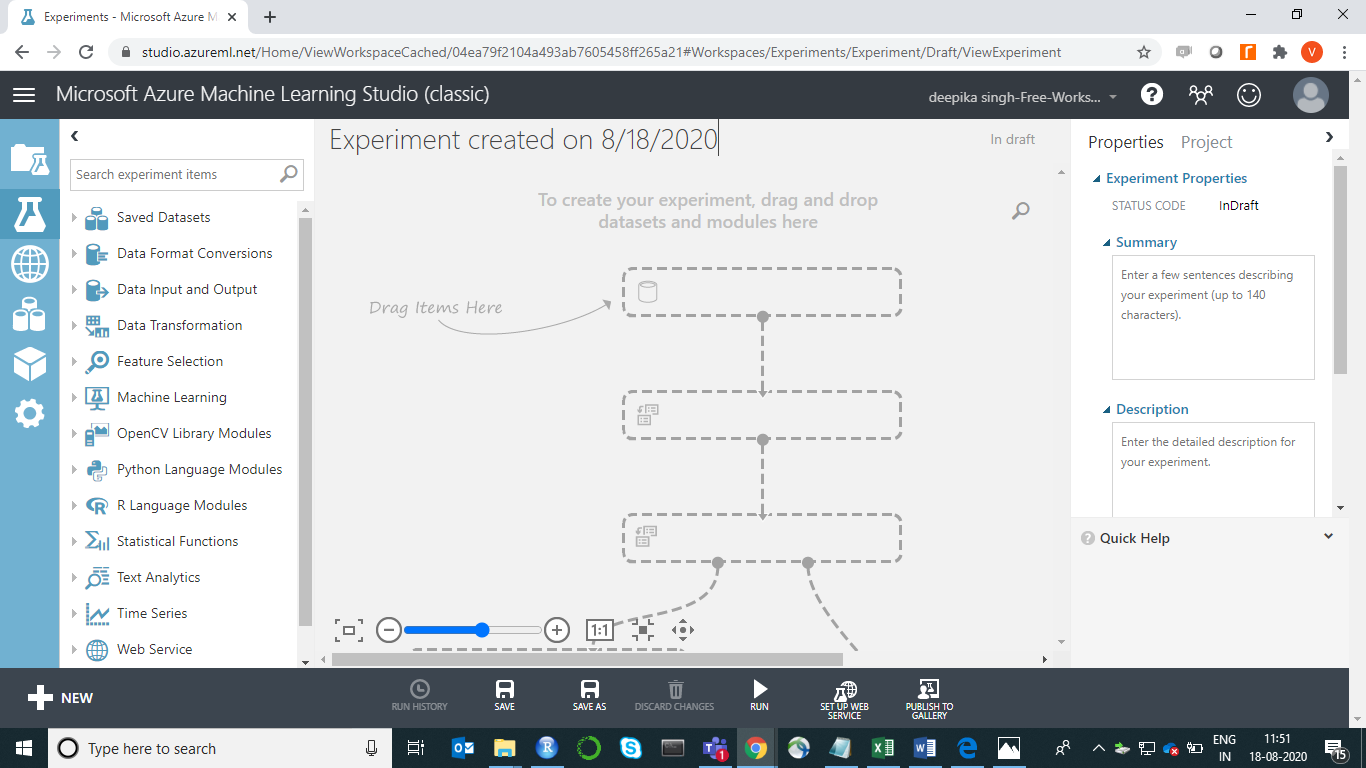
您已准备好加载数据。有许多可用于数据导入的选项。例如,如果您想从本地系统上传文件,请单击NEW,然后选择DATASET选项。

上面的选择将打开一个窗口,如下所示,可用于从本地系统上传数据集。
加载数据后,您可以在“已保存的数据集”选项中看到它。文件名为data_cleaning.csv。下一步是将其从“已保存的数据集”列表拖到工作区并将其命名为Cleaning Data。如下所示。
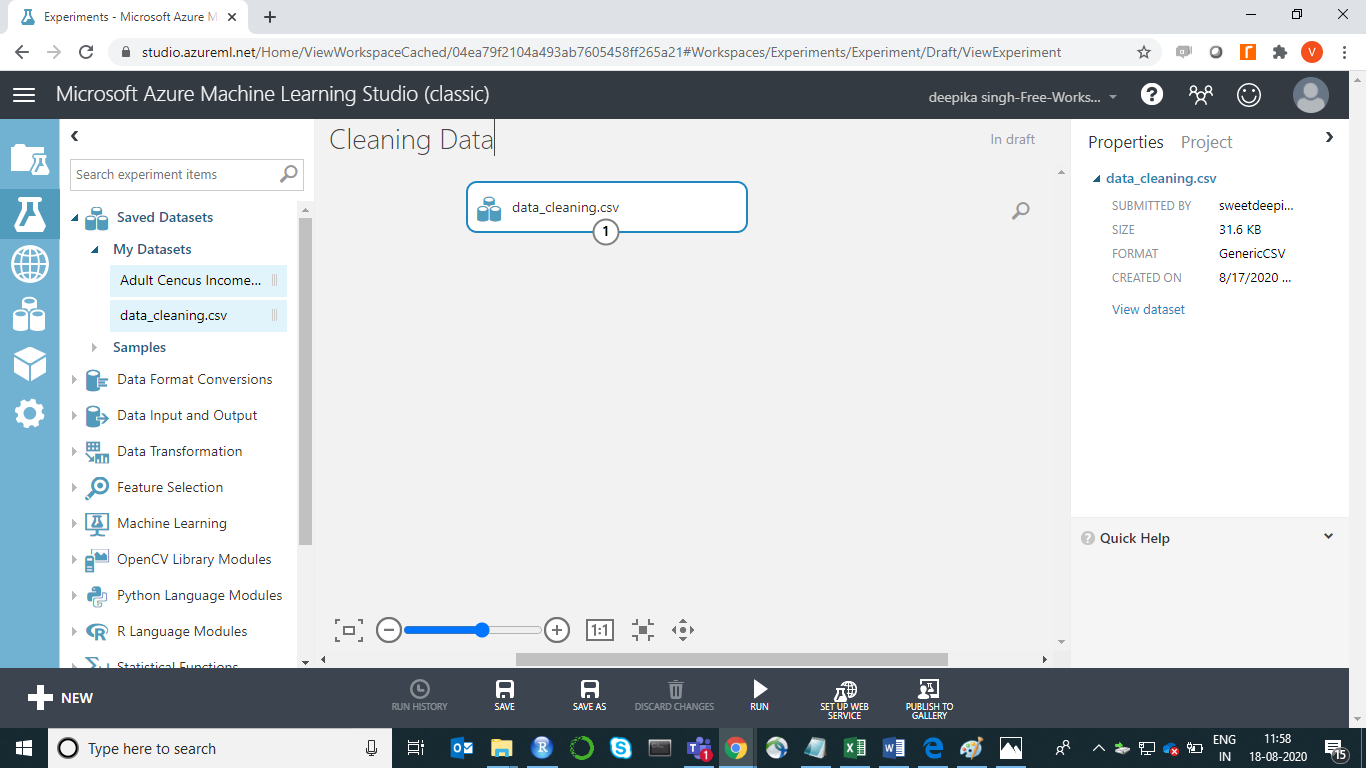
您现在已将数据加载到工作区中。
探索数据
要探索数据,请右键单击并选择“可视化”选项,如下所示。
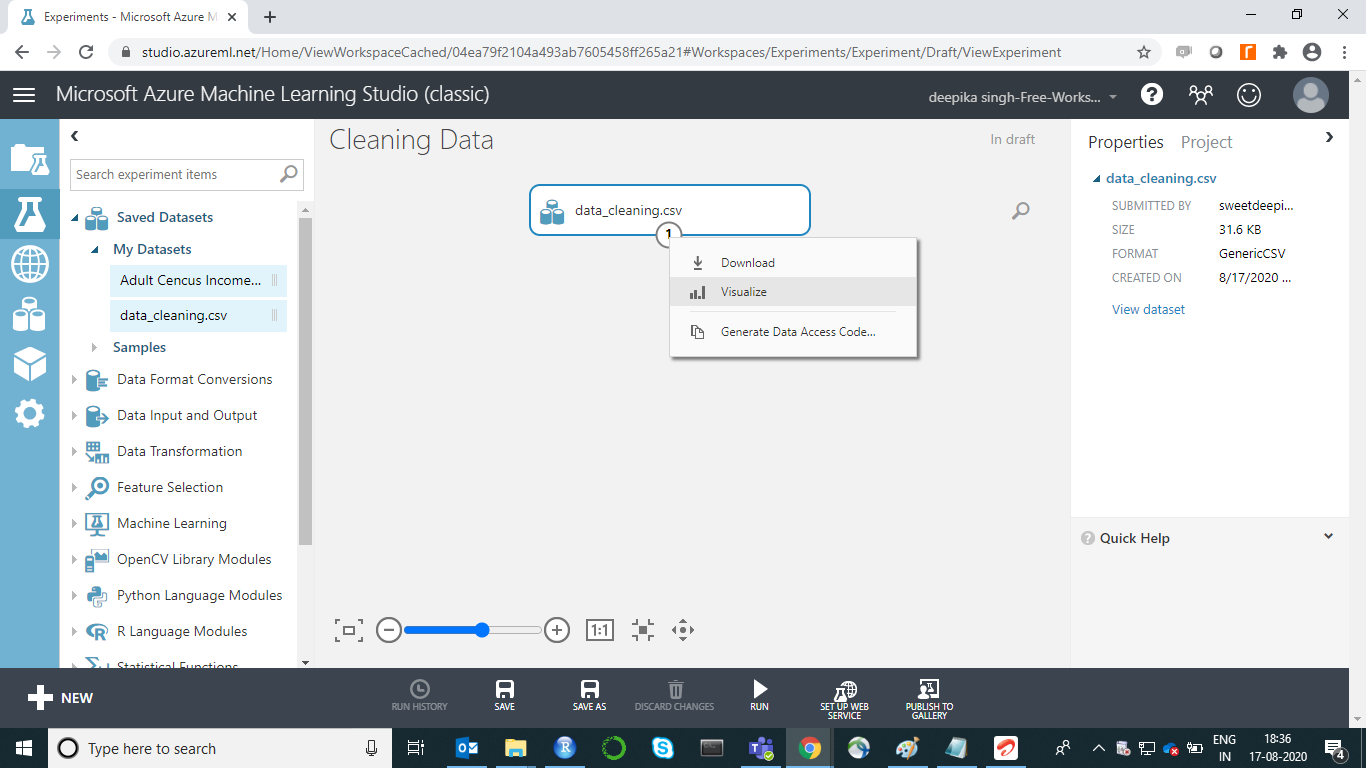
上面的选择打开了如下所示的窗口。有 600 行和 9 列。
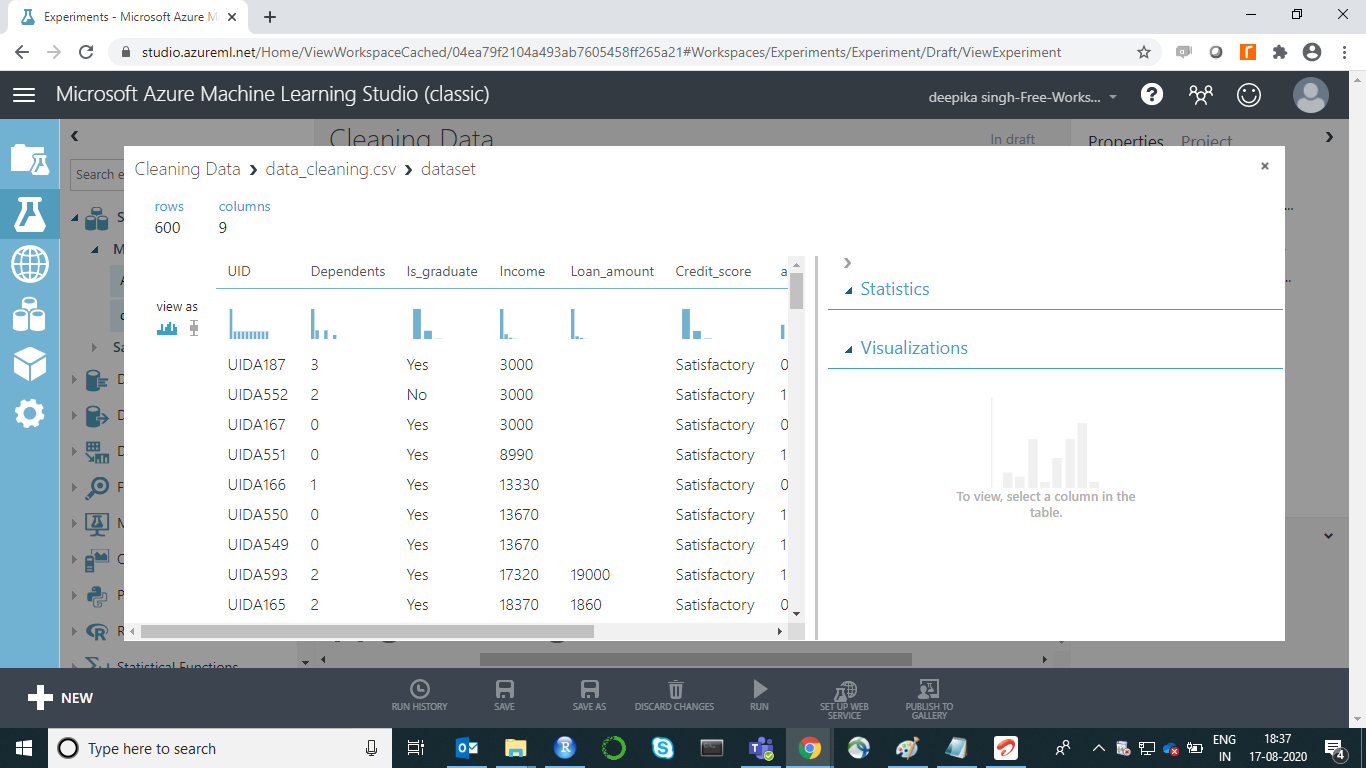
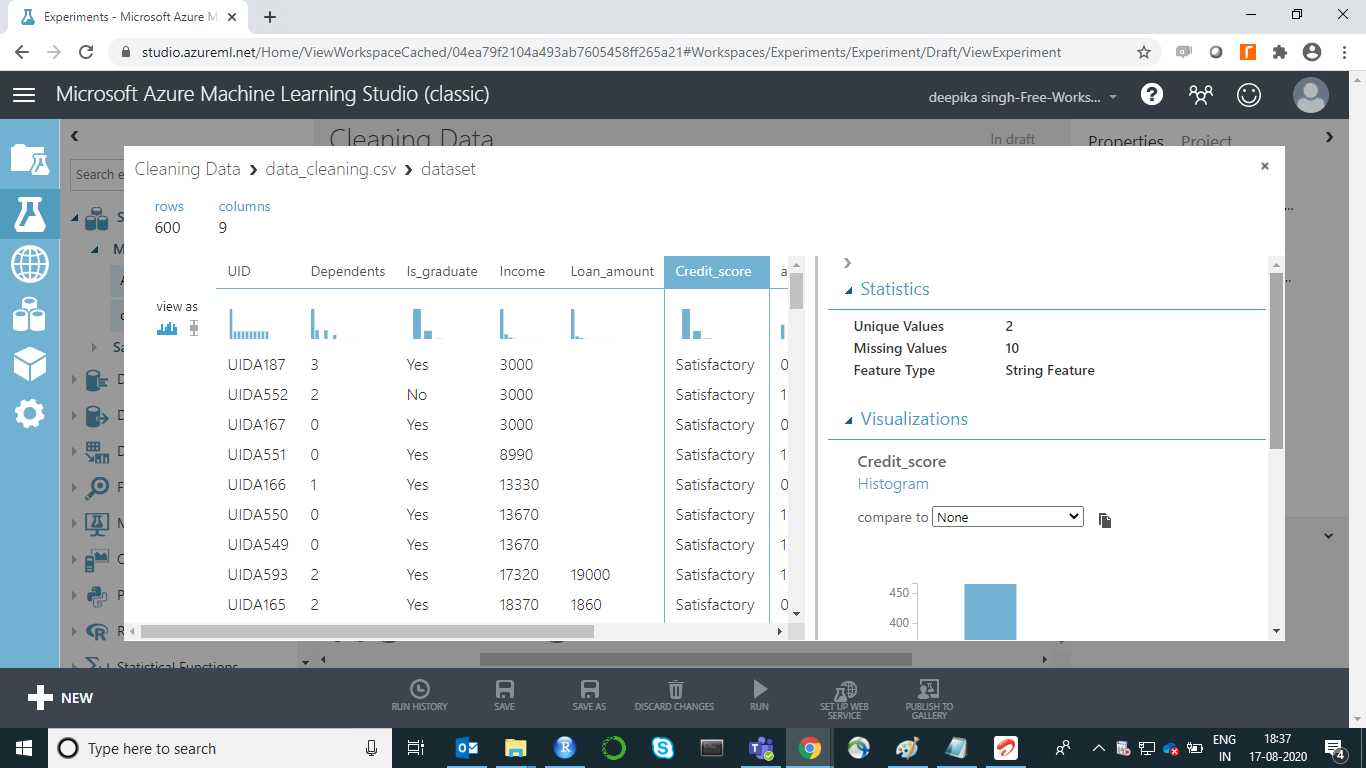
如果您选择任何变量,将显示其统计信息。例如,下图显示了有关变量Credit_score的基本详细信息。输出显示Credit_score中有十个缺失值,并且它采用两个唯一值。
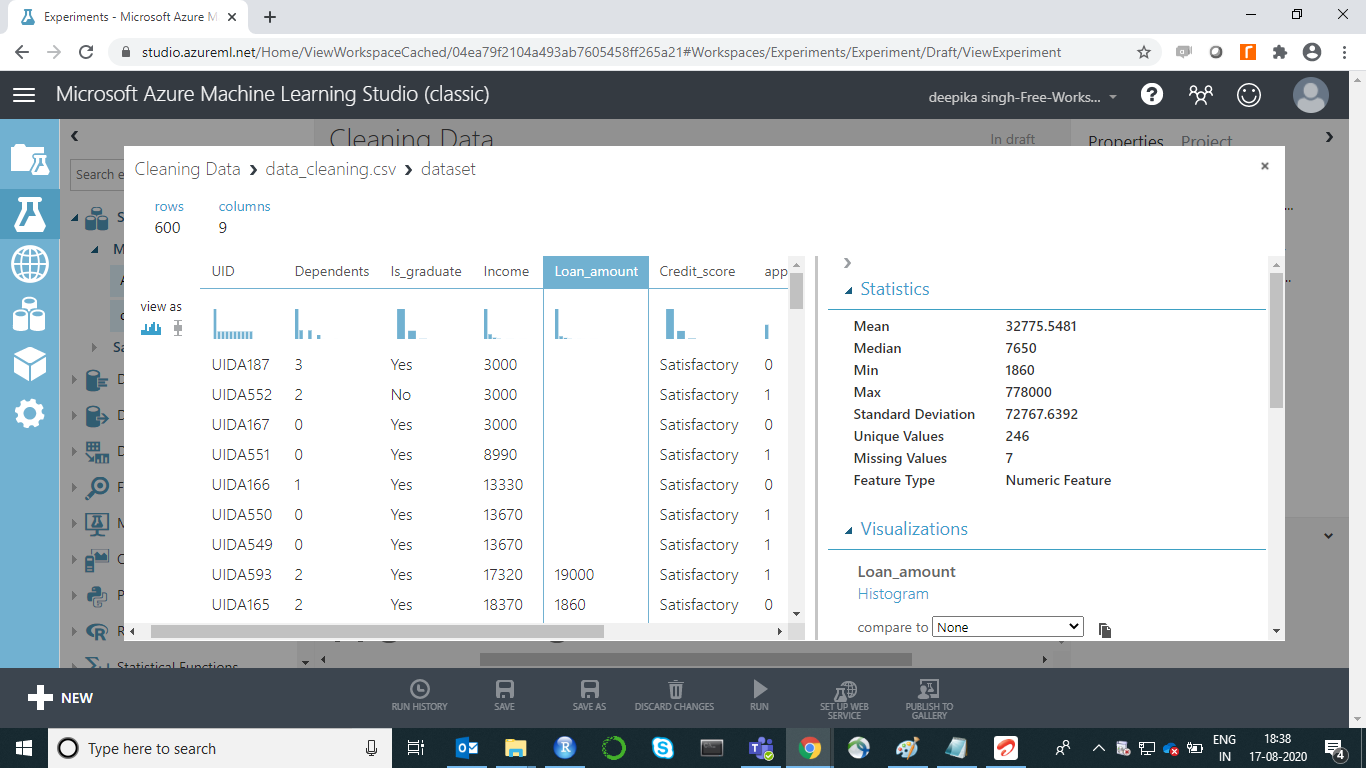
类似地,我们可以查看连续变量Loan_amount。下面的输出显示描述性统计数据的度量 - 平均值、中位数、最小值、最大值和标准差。
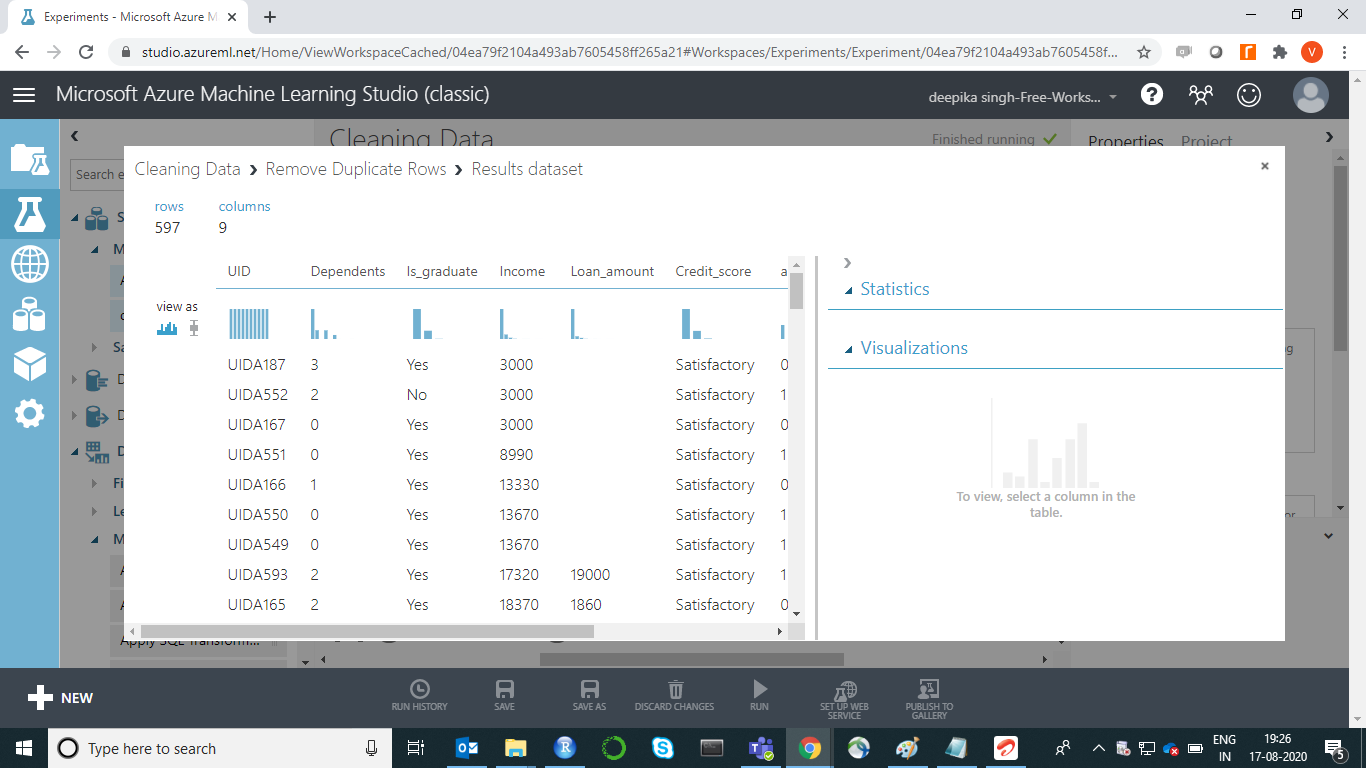
删除重复项
数据中常见的错误之一是存在重复记录。此类记录毫无用处,必须删除。在我们的数据集中,UID是唯一标识符变量,将用于删除重复记录。使用Azure 机器学习工作室中的“删除重复行”模块从数据集中删除潜在的重复项。首先将“删除重复行”模块拖到工作区中。然后将数据集连接到模块。
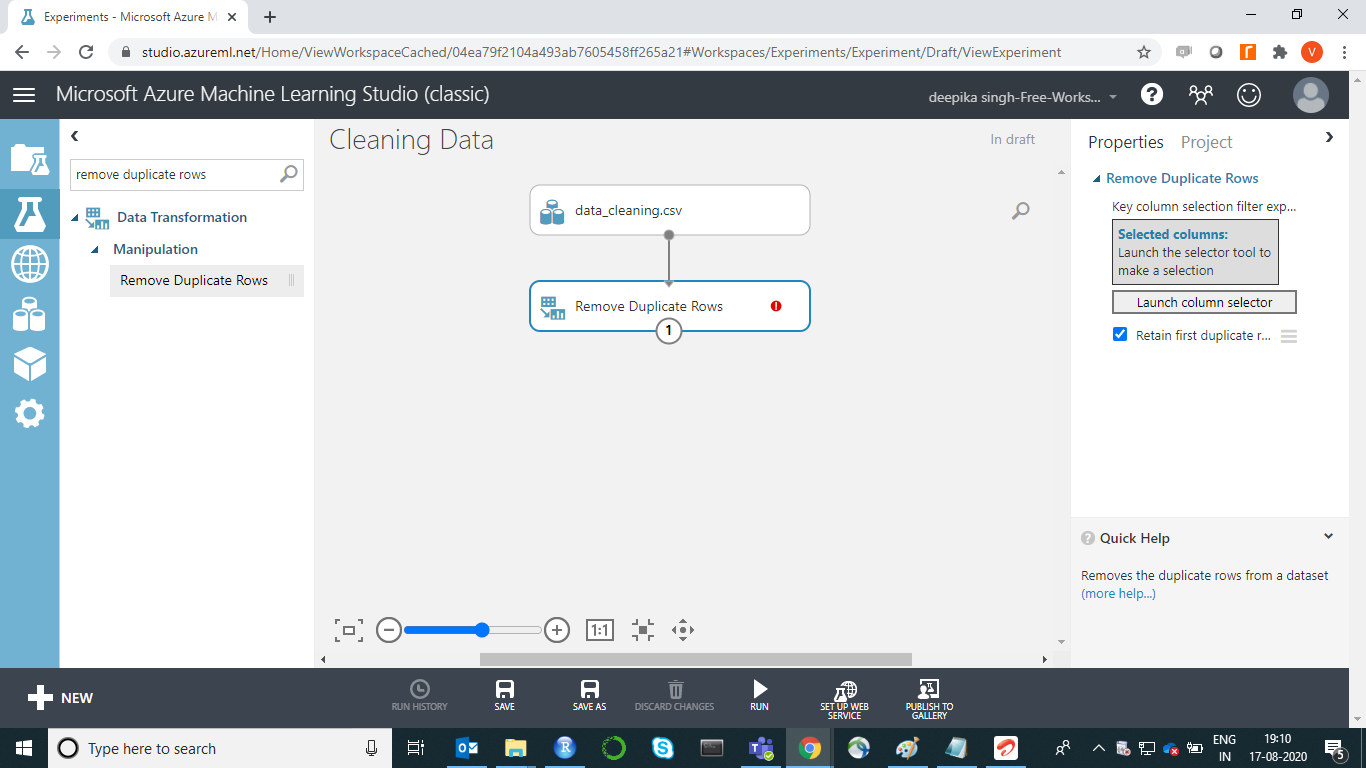
接下来,单击启动列选择器以选择用于识别重复项的列。这可以在属性窗格中找到。选择变量UID。
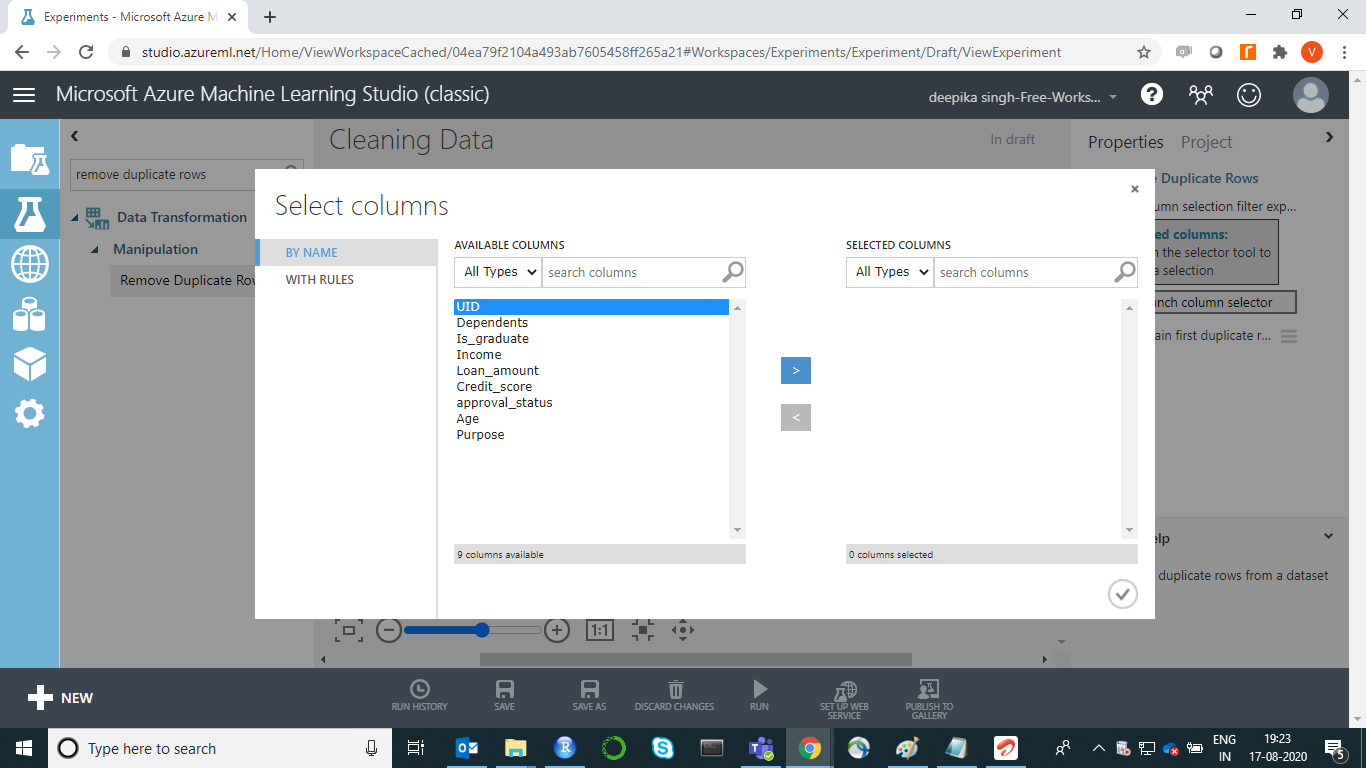
上述步骤将设置模块。此外,选中“保留第一个重复行”复选框以指示在发现重复项时返回哪一行。如果选中,则在结果数据集中返回第一行,其他行将被丢弃。最后,单击“运行”。
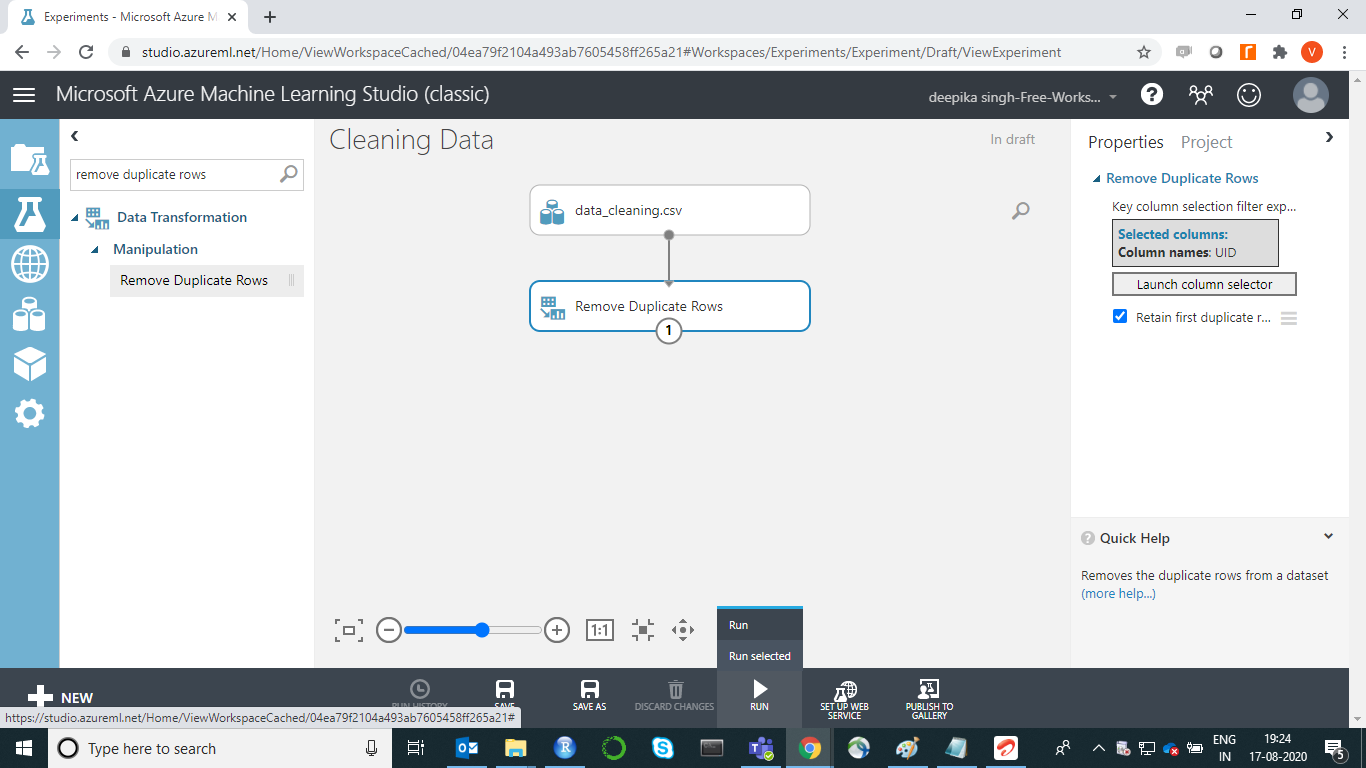
要检查结果,请右键单击“删除重复行”模块的输出端口,然后单击“可视化”。
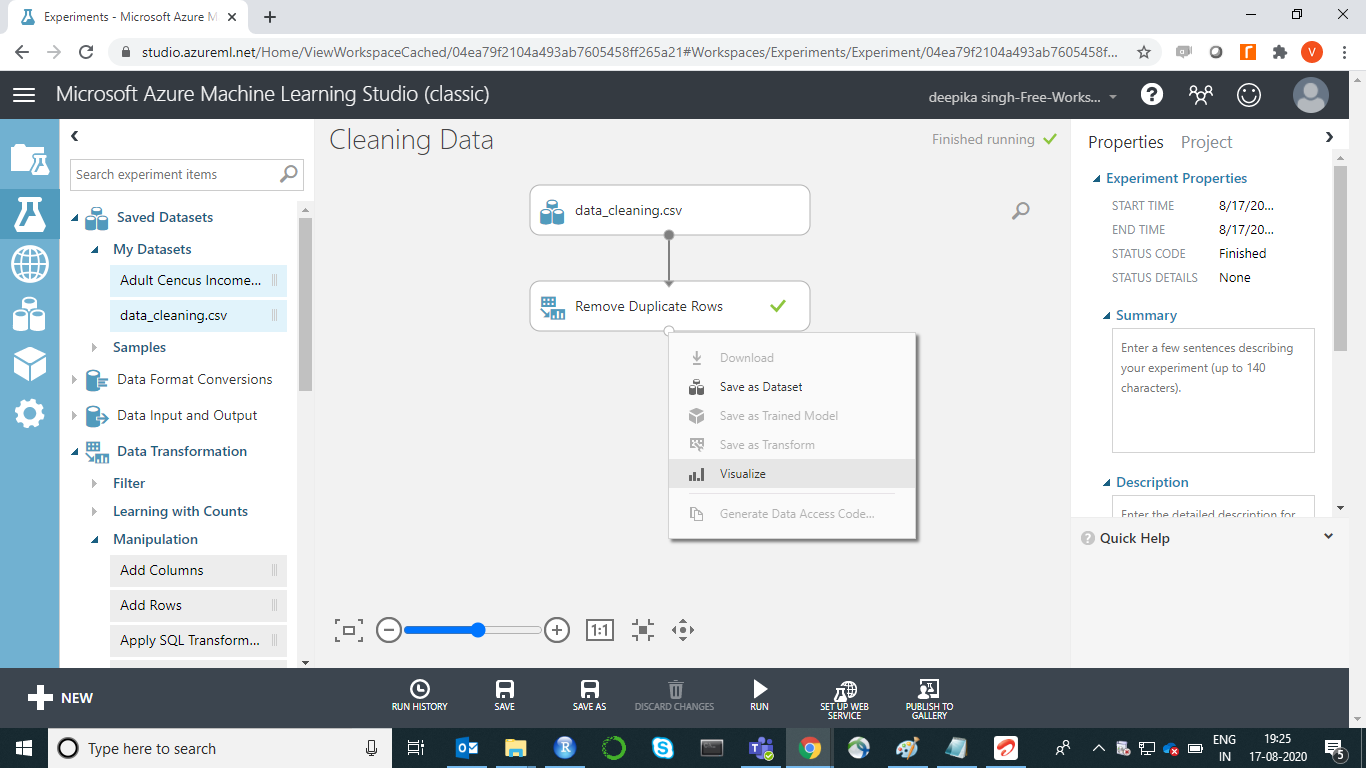
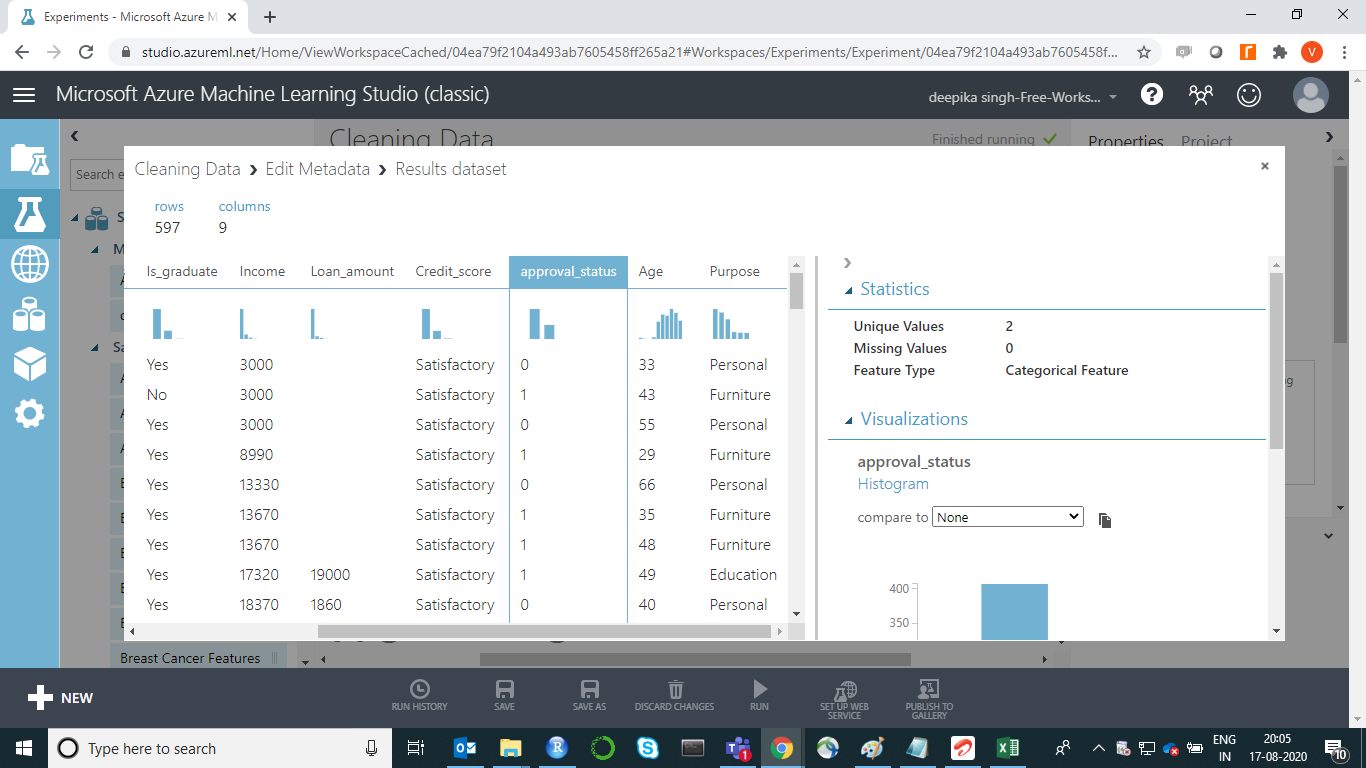
结果显示数据集中有 3 个重复项已被删除。最终数据有 597 行和 9 列。
转换数据类型
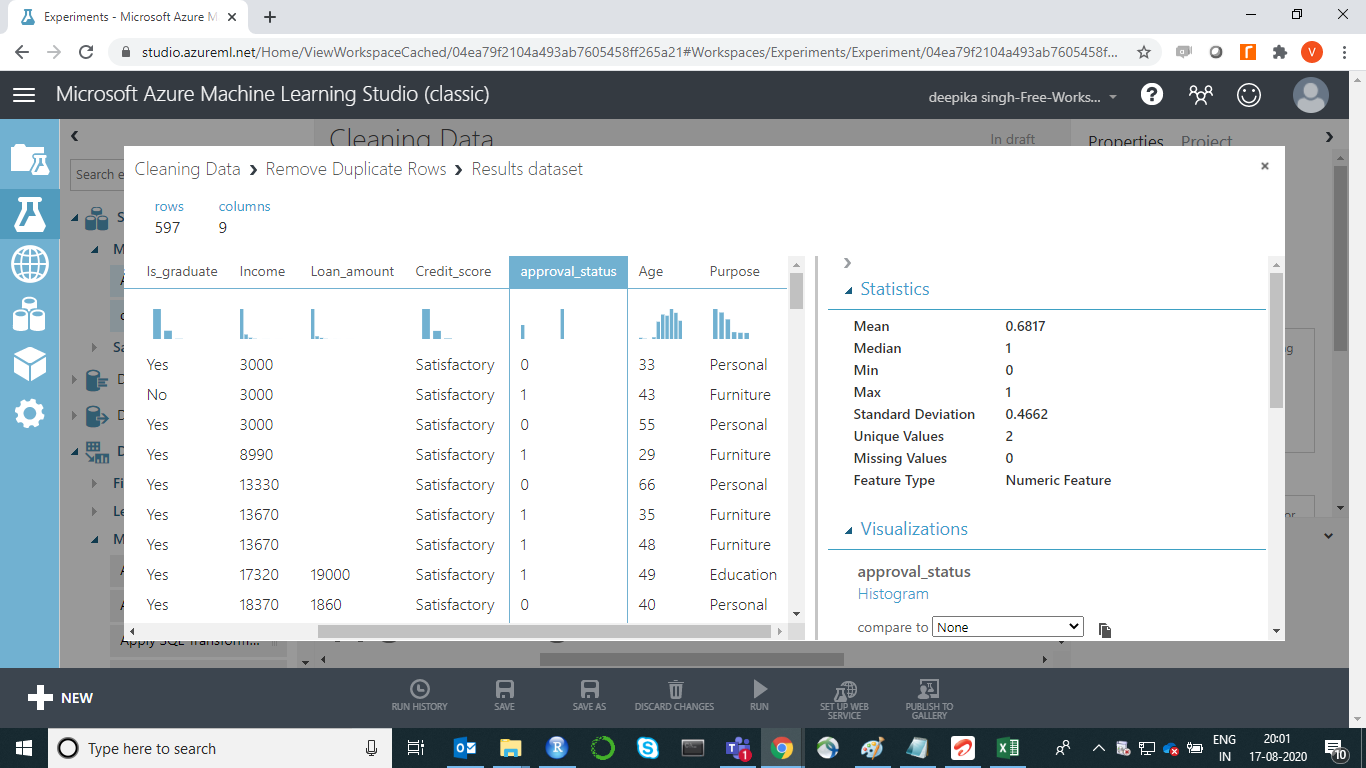
机器学习要求变量具有正确的数据类型。例如,approval_status变量是分类变量,但显示为数字特征。
还有其他变量也需要转换为分类变量。首先在搜索栏中输入编辑元数据以找到编辑元数据模块,然后将其拖到工作区中,如下所示。
下一步是单击位于工作区右侧的启动列选择器选项,并从可用列中选择要转换为正确数据类型的变量。这将生成下面的输出。
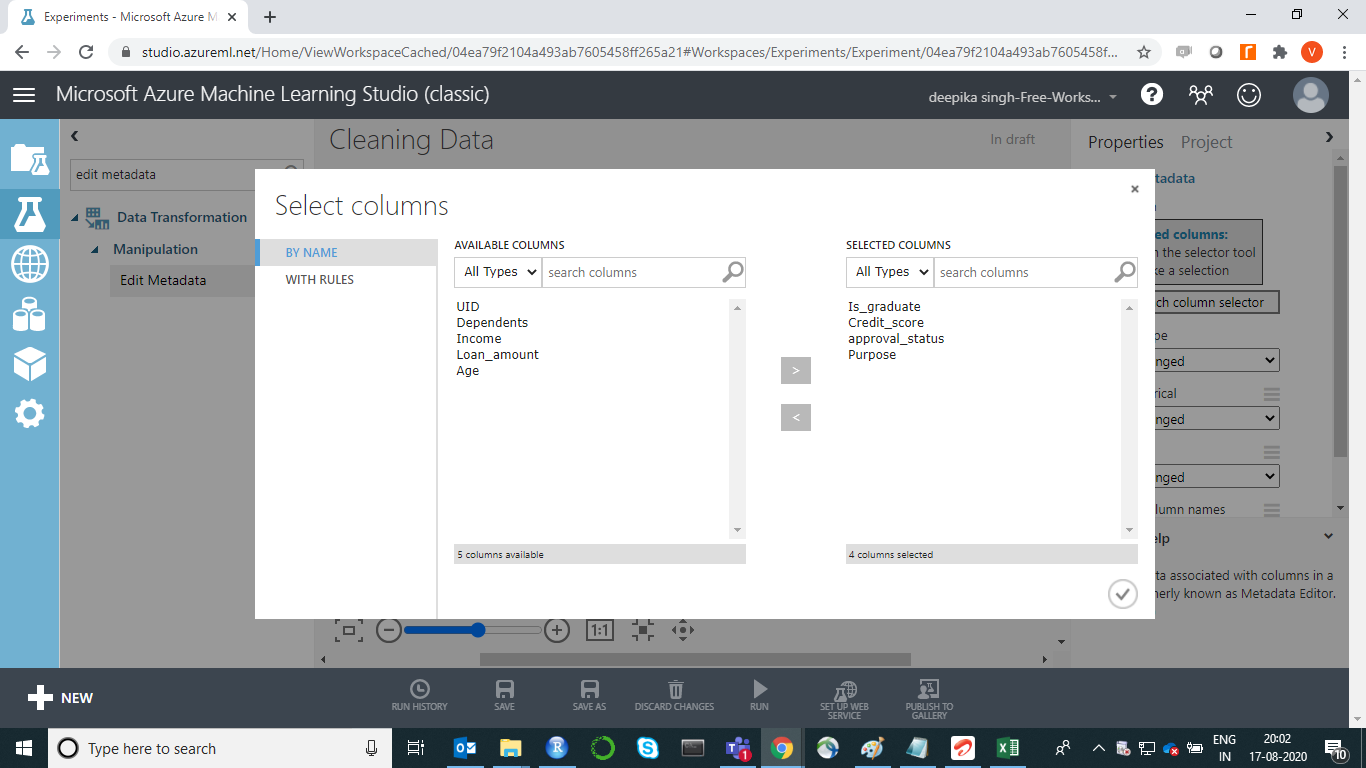
一旦做出选择,所选列将显示在工作区右侧的“所选列”下。
接下来,从Categorical下的下拉选项中选择Make categorical选项。接下来,单击工作区底部的RUN按钮。
要检查结果,请右键单击“编辑元数据”模块的输出端口,然后单击“可视化” 。变量approval_status的输出显示它现在是一个分类变量。
处理缺失值
另一项重要的数据清理任务是处理缺失值。此数据在数值变量(Age、Loan_amount和Dependents)和分类变量(Credit_score和Is_graduate)中均有缺失值。
处理缺失值的方法有很多种。一种常用方法是使用集中趋势度量来填补缺失值。您将分别使用平均值和众数来替换数字和分类特征中的缺失值。
免责声明:本内容来源于第三方作者授权、网友推荐或互联网整理,旨在为广大用户提供学习与参考之用。所有文本和图片版权归原创网站或作者本人所有,其观点并不代表本站立场。如有任何版权侵犯或转载不当之情况,请与我们取得联系,我们将尽快进行相关处理与修改。感谢您的理解与支持!





































请先 登录后发表评论 ~